> ## Documentation Index
> Fetch the complete documentation index at: https://braintrust.dev/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Manage datasets
> Organize datasets with tags and stars, pin versions with snapshots, validate with schemas, and edit records programmatically.
export const feature_0 = "Snapshots"
export const verb_0 = "are"
After creating a dataset, you'll typically organize, version, and modify it over time. Use the UI to tag, snapshot, and validate datasets at the dataset level, and use the SDK or the `bt` CLI to filter and edit individual records.
## Organize datasets
### Tag and star datasets
You can tag and star datasets to organize and find them in the datasets list. Tagging a dataset adds metadata that can be used to filter and group records, while starring a dataset causes it to sort first in the datasets table and dataset picker dropdowns.
To tag datasets:
1. Go to [** Datasets**](https://www.braintrust.dev/app/~/datasets).
2. Select one or more datasets.
3. Click ** Tag** in the toolbar.
4. Select or create tags to apply.
Tags are configured at the project level and shared across all objects — logs, experiments, dataset records, and entire datasets. See [project tag settings](/admin/projects#add-tags).
To star a dataset, click the **star icon** next to the dataset's name in the datasets list.
### Save snapshots
{feature_0} {verb_0} only available on [Pro and Enterprise plans](/plans-and-limits#plans).
Snapshots are named checkpoints of a dataset at a specific point in time. Save a snapshot to preserve the current state before making changes, or to pin a specific version for experiments and environments.
1. Go to [** Datasets**](https://www.braintrust.dev/app/~/datasets).
2. Open your dataset.
3. Click **Snapshots** > **+ Save snapshot** in the toolbar.
This option is available only when the dataset is non-empty and has changed since the last snapshot was saved.
From the **Snapshots** dropdown, you can also:
* **Rename**: Give the snapshot a descriptive name.
* **View**: Open the snapshot in a read-only viewer.
* **Evaluate in experiment** or **Evaluate in playground**: Run an eval using the snapshot's data.
* **Environments**: Assign the snapshot to one or more [environments](/deploy/environments). See [Assign to environments](/annotate/datasets/use-in-evaluations#assign-to-environments).
* **Restore**: Roll the dataset back to the snapshot's state.
* **Delete**: Permanently remove the snapshot.
To create a snapshot, fetch a row from the dataset to get the current `xact_id`, then call [`POST /v1/dataset_snapshot`](/api-reference/datasetsnapshots/create-dataset_snapshot). The dataset must be non-empty — an empty dataset has no `xact_id` to snapshot.
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
const datasetId = "";
// Fetch a row to get the current xact_id
const fetchResp = await fetch(
`https://api.braintrust.dev/v1/dataset/${datasetId}/fetch?limit=1`,
{ headers: { Authorization: `Bearer ${process.env.BRAINTRUST_API_KEY}` } },
);
const { events } = await fetchResp.json();
if (events.length === 0) {
throw new Error("Cannot create a snapshot of an empty dataset.");
}
const xactId = events[0]._xact_id;
// Create the snapshot
await fetch("https://api.braintrust.dev/v1/dataset_snapshot", {
method: "POST",
headers: {
Authorization: `Bearer ${process.env.BRAINTRUST_API_KEY}`,
"Content-Type": "application/json",
},
body: JSON.stringify({ dataset_id: datasetId, name: "my-snapshot", xact_id: xactId }),
});
```
```python theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import os
import httpx
dataset_id = ""
# Fetch a row to get the current xact_id
resp = httpx.get(
f"https://api.braintrust.dev/v1/dataset/{dataset_id}/fetch",
params={"limit": 1},
headers={"Authorization": f"Bearer {os.environ['BRAINTRUST_API_KEY']}"},
)
events = resp.json()["events"]
if not events:
raise ValueError("Cannot create a snapshot of an empty dataset.")
xact_id = events[0]["_xact_id"]
# Create the snapshot
httpx.post(
"https://api.braintrust.dev/v1/dataset_snapshot",
json={"dataset_id": dataset_id, "name": "my-snapshot", "xact_id": xact_id},
headers={"Authorization": f"Bearer {os.environ['BRAINTRUST_API_KEY']}"},
)
```
Use [`GET /v1/dataset_snapshot`](/api-reference/datasetsnapshots/list-dataset_snapshots), [`PATCH /v1/dataset_snapshot/{id}`](/api-reference/datasetsnapshots/partially-update-dataset_snapshot), and [`DELETE /v1/dataset_snapshot/{id}`](/api-reference/datasetsnapshots/delete-dataset_snapshot) to list, rename, and delete snapshots.
Use [`bt datasets snapshots`](/reference/cli/datasets#bt-datasets-snapshots) to create, list, restore, and delete snapshots from the CLI:
```bash theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
# Snapshot the dataset's current state
bt datasets snapshots create my-dataset baseline
# List saved snapshots
bt datasets snapshots list my-dataset
# Restore the dataset to a snapshot
bt datasets snapshots restore my-dataset --name baseline
# Delete a snapshot
bt datasets snapshots delete my-dataset baseline
```
See the [`bt datasets snapshots`](/reference/cli/datasets#bt-datasets-snapshots) reference for all flags.
You can also save, list, and restore snapshots from [Loop](/loop#manage-dataset-versions) when working on a dataset page.
### Define schemas
If you want to ensure all records have the same structure or make editing easier, define JSON schemas for your dataset fields. Schemas are particularly useful when multiple team members are manually adding records or when you need strict data validation.
Dataset schemas enable:
* **Validation**: Catch structural errors when adding or editing records.
* **Form-based editing**: Edit records with intuitive forms instead of raw JSON.
* **Documentation**: Make field expectations explicit for your team.
To define a schema:
1. Go to [** Datasets**](https://www.braintrust.dev/app/~/datasets).
2. Open your dataset.
3. Click **Field schemas** in the toolbar.
4. Select the field you want to define a schema for (`input`, `expected`, or `metadata`).
5. Click **Infer schema** to automatically generate a schema from the first 100 records, or manually define your schema structure.
6. Toggle **Enforce** to enable validation. When enabled:
* New records must conform or show validation errors.
* Existing non-conforming records display warnings.
* Form editing validates input as you type.
Enforcement is UI-only and doesn't affect SDK inserts or updates.
## Edit datasets
Read, update, and delete individual records programmatically.
### Filter records
Filter dataset records using the **Filter** button in the dataset table. You can filter by any field — `input`, `expected`, `metadata`, `tags`, or scores — using SQL expressions.
1. Go to [** Datasets**](https://www.braintrust.dev/app/~/datasets) and open your dataset.
2. Click **Filter**.
3. Add one or more filter conditions.
When you create an [experiment](/evaluate/run-evaluations#create-from-scratch) from a filtered dataset view, the active filters are carried over so the run is scoped to the same subset of records.
Read and filter datasets using `_internal_btql` to control which records are returned:
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import { initDataset } from "braintrust";
// Read all records
const dataset = initDataset("My App", { dataset: "Customer Support" });
for await (const row of dataset) {
console.log(row);
}
// Filter by metadata
const premiumDataset = initDataset("My App", {
dataset: "Customer Support",
_internal_btql: {
filter: { btql: "metadata.category = 'premium'" },
limit: 100,
},
});
for await (const row of premiumDataset) {
console.log(row);
}
// Sort by creation date
const sortedDataset = initDataset("My App", {
dataset: "Customer Support",
_internal_btql: {
sort: [{ expr: { btql: "created" }, dir: "desc" }],
limit: 50,
},
});
// Combine filters and sorts
const recentSupport = initDataset("My App", {
dataset: "Customer Support",
_internal_btql: {
filter: {
btql: "metadata.category = 'support' and created > now() - interval 7 day",
},
sort: [{ expr: { btql: "created" }, dir: "desc" }],
limit: 1000,
},
});
```
```python theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import braintrust
# Read all records
dataset = braintrust.init_dataset(project="My App", name="Customer Support")
for row in dataset:
print(row)
# Filter by metadata
premium_dataset = braintrust.init_dataset(
project="My App",
name="Customer Support",
_internal_btql={
"filter": {"btql": "metadata.category = 'premium'"},
"limit": 100,
},
)
for row in premium_dataset:
print(row)
# Sort by creation date
sorted_dataset = braintrust.init_dataset(
project="My App",
name="Customer Support",
_internal_btql={
"sort": [{"expr": {"btql": "created"}, "dir": "desc"}],
"limit": 50,
},
)
# Combine filters and sorts
recent_support = braintrust.init_dataset(
project="My App",
name="Customer Support",
_internal_btql={
"filter": {"btql": "metadata.category = 'support' and created > now() - interval 7 day"},
"sort": [{"expr": {"btql": "created"}, "dir": "desc"}],
"limit": 1000,
},
)
```
For more information on SQL syntax and available operators, see the [SQL reference documentation](/reference/sql).
### Update records
Update existing records by `id`:
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import { initDataset } from "braintrust";
const dataset = initDataset("My App", { dataset: "Customer Support" });
// Insert a record
const id = dataset.insert({
input: { question: "How do I reset my password?" },
expected: { answer: "Click 'Forgot Password' on the login page." },
});
// Update the record
dataset.update({
id,
metadata: { reviewed: true, difficulty: "easy" },
});
await dataset.flush();
```
```python theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import braintrust
dataset = braintrust.init_dataset(project="My App", name="Customer Support")
# Insert a record
id = dataset.insert(
input={"question": "How do I reset my password?"},
expected={"answer": "Click 'Forgot Password' on the login page."},
)
# Update the record
dataset.update(
id=id,
metadata={"reviewed": True, "difficulty": "easy"},
)
dataset.flush()
```
The `update()` method applies a merge strategy: only the fields you provide will be updated, and all other existing fields in the record will remain unchanged.
Use the [`bt datasets update`](/reference/cli/datasets#bt-datasets-update) CLI command (also available as `add` and `refresh`) to upsert records by stable ID:
```bash theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
bt datasets update my-dataset --file records.jsonl
bt datasets add my-dataset --rows '[{"id":"case-2","input":{"text":"bye"},"expected":"goodbye"}]'
bt datasets refresh my-dataset --file records.jsonl --id-field metadata.case_id
```
| Flag | Description |
| ------------------- | -------------------------------------------------------------------- |
| `--file ` | Input JSONL file |
| `--rows ` | Inline JSON array of rows |
| `--id-field ` | Dot-separated path to use as the record ID instead of the `id` field |
Each row must have a stable ID via the `id` field or `--id-field`. Rows without IDs are rejected.
These commands upsert rows directly — rows not in the input are not deleted. `refresh` fails if the dataset does not exist.
Use `--id-field` to extract an ID from a nested field (e.g., `metadata.case_id`). Escape literal dots as `\.` and literal backslashes as `\\`.
### Delete records
To delete specific records:
1. Go to [** Datasets**](https://www.braintrust.dev/app/~/datasets) and open your dataset.
2. Select the records you want to delete.
3. Click **Delete** in the toolbar.
To delete an entire dataset:
1. Go to [** Datasets**](https://www.braintrust.dev/app/~/datasets).
2. Select the dataset you want to delete.
3. Click **Delete** in the toolbar.
Remove individual records by `id`:
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import { initDataset } from "braintrust";
const dataset = initDataset("My App", { dataset: "Customer Support" });
// Insert a record
const id = dataset.insert({
input: { question: "Test question" },
expected: { answer: "Test answer" },
});
// Delete the record
await dataset.delete(id);
await dataset.flush();
```
```python theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import braintrust
dataset = braintrust.init_dataset(project="My App", name="Customer Support")
# Insert a record
id = dataset.insert(
input={"question": "Test question"},
expected={"answer": "Test answer"},
)
# Delete the record
dataset.delete(id)
dataset.flush()
```
Use the [`bt datasets delete`](/reference/cli/datasets#bt-datasets-delete) CLI command to delete a dataset and all its records. To delete individual records, use the UI or the SDK.
```bash theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
bt datasets delete my-dataset
```
This operation is irreversible. All records in the dataset are permanently deleted.
### Flush records
The Braintrust SDK flushes records asynchronously and installs exit handlers, but these hooks are not always respected (e.g., by certain runtimes or when exiting a process abruptly). Call `flush()` to ensure records are written:
```typescript theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import { initDataset } from "braintrust";
const dataset = initDataset("My App", { dataset: "Customer Support" });
// Insert records
dataset.insert({
input: { question: "How do I reset my password?" },
expected: { answer: "Click 'Forgot Password' on the login page." },
});
// Flush to ensure all records are saved
await dataset.flush();
```
```python theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
import braintrust
dataset = braintrust.init_dataset(project="My App", name="Customer Support")
# Insert records
dataset.insert(
input={"question": "How do I reset my password?"},
expected={"answer": "Click 'Forgot Password' on the login page."},
)
# Flush to ensure all records are saved
dataset.flush()
```
## Review datasets
You can configure human review workflows to label and evaluate dataset records with your team.
### Configure review scores
Configure categorical scores to allow reviewers to rapidly label records. See [Configure review scores](/annotate/human-review#configure-review-scores) for details.
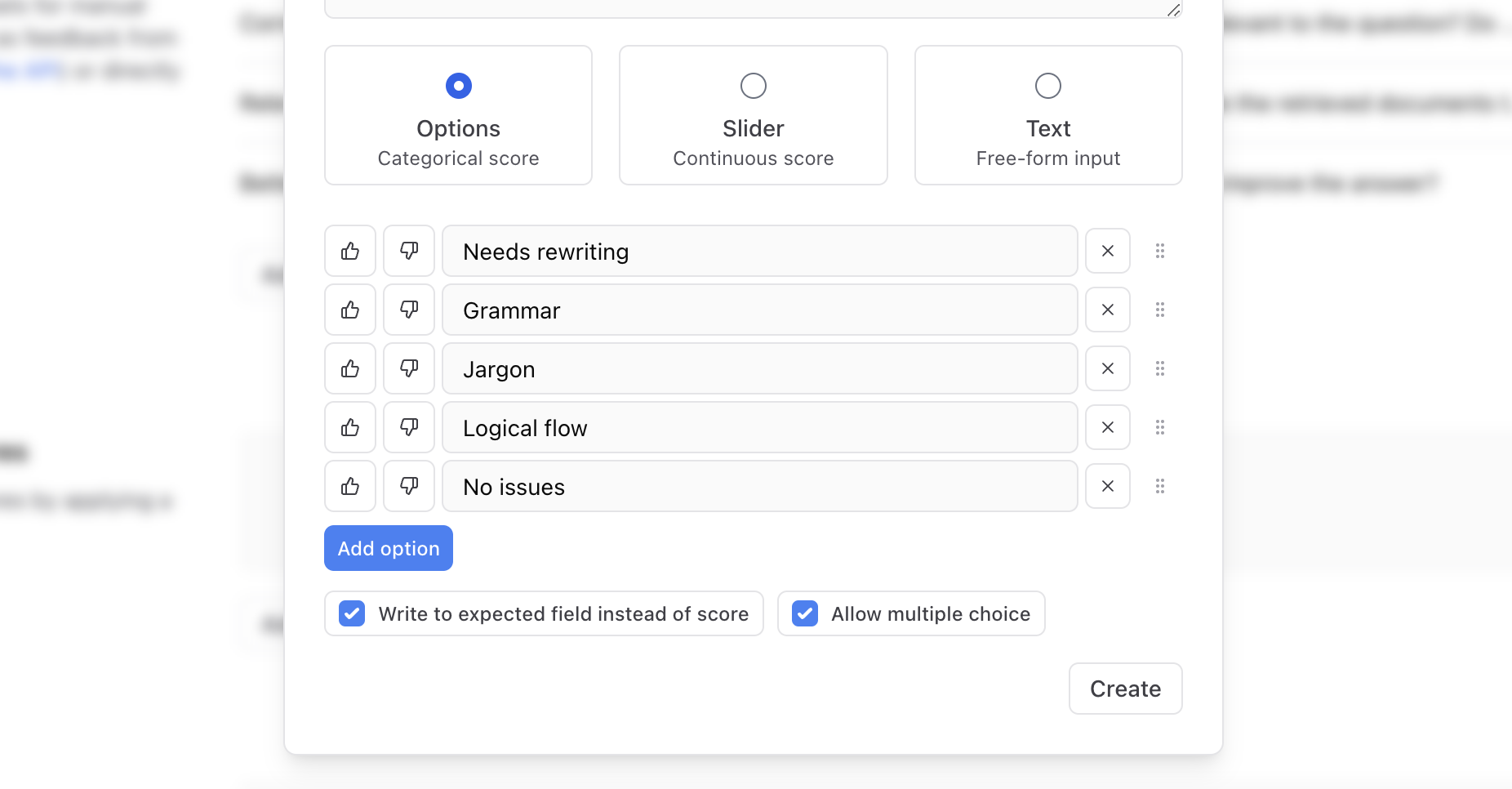 ### Assign rows for review
Assign dataset rows to team members for review, analysis, or follow-up action. Assignments are particularly useful for distributing review work across multiple team members.
See [Assign rows for review](/annotate/human-review/manage-review-work#assign-rows-for-review) for details.
### Create custom dataset views
Custom dataset views let you build tailored interfaces for reviewing individual dataset rows. Open a dataset row, select **Views**, and describe the interface you want in natural language. Loop generates a customizable React component your team can use directly in Braintrust.
See [Custom dataset views](/annotate/custom-views#create-views) for guidance on creating, editing, and sharing views.
## Customize table views
Tailor how dataset data is displayed in the UI by adding computed columns, saving custom views, and sharing views across projects.
### Create custom columns
Extract values from records using [custom columns](/evaluate/interpret-results#create-custom-columns). Use SQL expressions to surface important fields directly in the table.
### Create custom table views
To create or update a custom table view:
1. Apply the filters and display settings you want.
2. Open the menu and select **Save view\...** or **Save view as...**.
Custom table views are visible to all project members. Creating or editing a table view requires the **Update** project permission.
### Set default table views
You can set default views at three levels:
* **Organization default**: Visible to all members when they open the page. This applies per page. For example, you can set separate organization defaults for Logs, Experiments, and Review. To set an organization default, you need the **Manage settings** organization permission (included by default in the **Owner** role). See [Access control](/admin/access-control) for details.
* **Project default**: Overrides the organization default for everyone viewing this project. To set a project default, you need the project-level **Update** permission. Project admins can set project defaults even without organization-level permissions. See [Access control](/admin/access-control) for details.
* **Personal default**: Overrides the project and organization defaults for you only. Personal defaults are stored in your browser, so they do not carry over across devices or browsers.
To set a default view:
1. Switch to the view you want by selecting it from the menu.
2. Open the menu again and hover over the currently selected view to reveal its submenu.
3. Choose **Set as personal default view**, **Set as project default view**, or **Set as organization default view**.
To clear a default view:
1. Open the menu and hover over the currently selected view to reveal its submenu.
2. Choose **Clear personal default view**, **Clear project default view**, or **Clear organization default view**.
Default view settings are mutually exclusive on a given view. Setting one type of default on a view automatically clears any other default that was previously set on the same view.
When a user opens a page, Braintrust loads the first match in this order: personal default, project default, organization default, then the standard "All ..." view (for example, "All logs view").
### Duplicate table views across projects
If you've built a useful custom table view in one project, you can duplicate it to another project via the API rather than recreating it from scratch. Datasets have two customizable views:
* Datasets list: The project's [** Datasets**](https://www.braintrust.dev/app/~/datasets) tab, where each row is a dataset.
* Single dataset table: The rows of data inside one dataset.
The following steps work for either. Choose the corresponding `view_type` in the API call.
1. Use the [list views](/api-reference/views/list-views) API endpoint to fetch the dataset views in your source project. Pass the following query parameters:
* `object_type=project`
* `object_id=`
* `view_type=dataset` for a single dataset table view, or `view_type=datasets` for the datasets list
```bash Single dataset theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
curl --request GET \
--url 'https://api.braintrust.dev/v1/view?object_type=project&object_id=&view_type=dataset' \
--header 'Authorization: Bearer '
```
```bash Datasets list theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
curl --request GET \
--url 'https://api.braintrust.dev/v1/view?object_type=project&object_id=&view_type=datasets' \
--header 'Authorization: Bearer '
```
2. In the response, find the view you want to duplicate and copy its `view_data` and `options` payloads.
3. Use the [create view](/api-reference/views/create-view) API endpoint to create the view in the destination project. Set `object_id` to the destination project ID.
```bash Single dataset theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
curl --request POST \
--url https://api.braintrust.dev/v1/view \
--header 'Authorization: Bearer ' \
--header 'Content-Type: application/json' \
--data '
{
"object_type": "project",
"object_id": "",
"view_type": "dataset",
"name": "",
"view_data": ,
"options":
}'
```
```bash Datasets list theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
curl --request POST \
--url https://api.braintrust.dev/v1/view \
--header 'Authorization: Bearer ' \
--header 'Content-Type: application/json' \
--data '
{
"object_type": "project",
"object_id": "",
"view_type": "datasets",
"name": "",
"view_data": ,
"options":
}'
```
## Share a dataset
Copy a dataset's URL from your browser to share it. For a portable link that resolves regardless of organization or project, use its ID:
```
https://www.braintrust.dev/app/object?object_type=dataset&object_id=
```
Visiting this URL redirects to the dataset's canonical page.
## Next steps
* [Use datasets in evaluations](/annotate/datasets/use-in-evaluations) with `Eval()`.
* [Track performance](/annotate/datasets/track-performance) across experiments.
### Assign rows for review
Assign dataset rows to team members for review, analysis, or follow-up action. Assignments are particularly useful for distributing review work across multiple team members.
See [Assign rows for review](/annotate/human-review/manage-review-work#assign-rows-for-review) for details.
### Create custom dataset views
Custom dataset views let you build tailored interfaces for reviewing individual dataset rows. Open a dataset row, select **Views**, and describe the interface you want in natural language. Loop generates a customizable React component your team can use directly in Braintrust.
See [Custom dataset views](/annotate/custom-views#create-views) for guidance on creating, editing, and sharing views.
## Customize table views
Tailor how dataset data is displayed in the UI by adding computed columns, saving custom views, and sharing views across projects.
### Create custom columns
Extract values from records using [custom columns](/evaluate/interpret-results#create-custom-columns). Use SQL expressions to surface important fields directly in the table.
### Create custom table views
To create or update a custom table view:
1. Apply the filters and display settings you want.
2. Open the menu and select **Save view\...** or **Save view as...**.
Custom table views are visible to all project members. Creating or editing a table view requires the **Update** project permission.
### Set default table views
You can set default views at three levels:
* **Organization default**: Visible to all members when they open the page. This applies per page. For example, you can set separate organization defaults for Logs, Experiments, and Review. To set an organization default, you need the **Manage settings** organization permission (included by default in the **Owner** role). See [Access control](/admin/access-control) for details.
* **Project default**: Overrides the organization default for everyone viewing this project. To set a project default, you need the project-level **Update** permission. Project admins can set project defaults even without organization-level permissions. See [Access control](/admin/access-control) for details.
* **Personal default**: Overrides the project and organization defaults for you only. Personal defaults are stored in your browser, so they do not carry over across devices or browsers.
To set a default view:
1. Switch to the view you want by selecting it from the menu.
2. Open the menu again and hover over the currently selected view to reveal its submenu.
3. Choose **Set as personal default view**, **Set as project default view**, or **Set as organization default view**.
To clear a default view:
1. Open the menu and hover over the currently selected view to reveal its submenu.
2. Choose **Clear personal default view**, **Clear project default view**, or **Clear organization default view**.
Default view settings are mutually exclusive on a given view. Setting one type of default on a view automatically clears any other default that was previously set on the same view.
When a user opens a page, Braintrust loads the first match in this order: personal default, project default, organization default, then the standard "All ..." view (for example, "All logs view").
### Duplicate table views across projects
If you've built a useful custom table view in one project, you can duplicate it to another project via the API rather than recreating it from scratch. Datasets have two customizable views:
* Datasets list: The project's [** Datasets**](https://www.braintrust.dev/app/~/datasets) tab, where each row is a dataset.
* Single dataset table: The rows of data inside one dataset.
The following steps work for either. Choose the corresponding `view_type` in the API call.
1. Use the [list views](/api-reference/views/list-views) API endpoint to fetch the dataset views in your source project. Pass the following query parameters:
* `object_type=project`
* `object_id=`
* `view_type=dataset` for a single dataset table view, or `view_type=datasets` for the datasets list
```bash Single dataset theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
curl --request GET \
--url 'https://api.braintrust.dev/v1/view?object_type=project&object_id=&view_type=dataset' \
--header 'Authorization: Bearer '
```
```bash Datasets list theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
curl --request GET \
--url 'https://api.braintrust.dev/v1/view?object_type=project&object_id=&view_type=datasets' \
--header 'Authorization: Bearer '
```
2. In the response, find the view you want to duplicate and copy its `view_data` and `options` payloads.
3. Use the [create view](/api-reference/views/create-view) API endpoint to create the view in the destination project. Set `object_id` to the destination project ID.
```bash Single dataset theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
curl --request POST \
--url https://api.braintrust.dev/v1/view \
--header 'Authorization: Bearer ' \
--header 'Content-Type: application/json' \
--data '
{
"object_type": "project",
"object_id": "",
"view_type": "dataset",
"name": "",
"view_data": ,
"options":
}'
```
```bash Datasets list theme={"theme":{"light":"github-light","dark":"github-dark-dimmed"}}
curl --request POST \
--url https://api.braintrust.dev/v1/view \
--header 'Authorization: Bearer ' \
--header 'Content-Type: application/json' \
--data '
{
"object_type": "project",
"object_id": "",
"view_type": "datasets",
"name": "",
"view_data": ,
"options":
}'
```
## Share a dataset
Copy a dataset's URL from your browser to share it. For a portable link that resolves regardless of organization or project, use its ID:
```
https://www.braintrust.dev/app/object?object_type=dataset&object_id=
```
Visiting this URL redirects to the dataset's canonical page.
## Next steps
* [Use datasets in evaluations](/annotate/datasets/use-in-evaluations) with `Eval()`.
* [Track performance](/annotate/datasets/track-performance) across experiments.